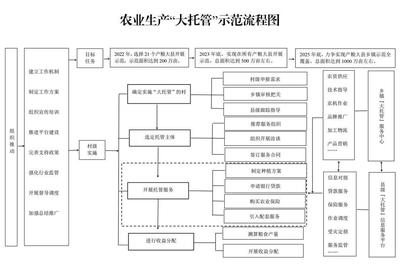
甘肅省立足省情農情,積極探索以農業生產托管服務為抓手,推動土地聯耕聯種、促進農業規模經營的新模式,為破解“誰來種地、怎么種好地”的難題提供了富有甘肅特色的解決方案。
農業生產托管服務,是指農戶等經營主體在不流轉土地經營權的條件下,將農業生產中的耕、種、防、收等全部或部分作業環節,委托給專業的服務組織完成的一種經營方式。在甘肅,這一模式正從試點探索走向全面拓展。
甘肅地形復雜,山地、高原、河谷交錯,耕地細碎化問題較為突出,直接制約了現代農業機械化和標準化的發展。為此,甘肅各地因地制宜,大力培育各類農業社會化服務組織,包括農機合作社、種植合作社、農業企業等,鼓勵它們為分散的小農戶提供“菜單式”、“全程式”等多種形式的托管服務。通過服務組織將分散的耕地集中起來,統一規劃、統一作業,實現了“聯耕聯種”,有效提高了土地、農機、技術的利用效率,降低了生產成本。
“聯耕聯種”的核心在于“聯”。一方面,它通過服務組織這個紐帶,將原本各自為戰的農戶聯合起來,形成了事實上的規模化生產單元;另一方面,它聯結了先進的農業技術、大型農機裝備和現代管理模式,使小農戶能夠共享現代農業發展的成果。例如,在河西走廊的糧食主產區,托管服務組織利用大型農機進行深松整地、精量播種、高效植保和聯合收割,糧食生產的全程機械化水平顯著提升,節本增效效果明顯。在定西、隴南等山地丘陵地區,托管服務則側重于關鍵環節,如機械收割、病蟲害統防統治等,有效緩解了勞動力短缺的困境。
拓展農業生產托管服務,有力地促進了甘肅農業的規模經營。這種規模經營并非簡單的土地集中,而是服務規模的擴大和生產環節的標準化、集約化。它保持了農戶的土地承包權,穩定了農村基本經營制度,同時通過服務的規模化,克服了小農生產的弊端,為發展節水農業、綠色農業、高效農業奠定了基礎。越來越多的農戶從繁重的體力勞動中解放出來,可以外出務工或從事其他產業,實現了多元增收。
當前,甘肅正進一步完善支持政策,加強服務標準制定、服務質量監測和行業規范管理,并積極探索金融、保險等要素與托管服務的深度融合,以破解服務組織發展中的資金、風險等瓶頸問題。持續拓展和深化的農業生產托管服務,將成為推動甘肅現代農業轉型升級、保障糧食安全和助力鄉村全面振興的重要引擎。